
들어가기 전
반복문자를 처리하는 것은 참 까다롭습니다. 의미를 파악하는데 문자의 빈도수가 영향을 줄 때도 있고(아래에 자세히 서술) 때론 학습에 방해가 될 때도 있습니다. 그래서 저는 해당 포스트에서 반복문자가 들어간 문자열(이하 반복문자열)을 처리하는 정규표현식에 대해 설명하고자 합니다.
목차
- 용어 설명
- 정규화 과정에서 반복문자를 남겨야 하는 이유
- 반복문자 정규화 기준 정의
- 정규화 과정 1 - 반복문자 탐지
- 정규화 과정 2 - 반복문자 교정하기
- 정리 및 마무리
1. 용어 설명
1. 문장
일반적인 문장을 의미합니다. 반복문자열이 포함될 수 있는 대상입니다.
"안녕하세요.", "재밌다 ㅋㅋㅋㅋㅋ", "어이가없네;;;;" , "ㅇㅇㄴㅇㅇㅇㄴㅇㅇㅇㄴㅇㅇㅇㄴㅇ"
2. 반복문자열
기존 문자열에서 문자 또는 단어가 띄어쓰기 없이 반복적으로 출현하는 문자열을 의미합니다.
"안녕하세요.", "재밌다 ㅋㅋㅋㅋㅋ", "어이가없네;;;;", "ㅇㅇㄴㅇㅇㅇㄴㅇㅇㅇㄴㅇㅇㅇㄴㅇ"
3. 반복문자
반복문자열에서 등장하는 반복되는 최소 단위를 의미합니다.
"안녕하세요.", "재밌다 ㅋㅋㅋㅋㅋ", "어이가없네;;;;" , "ㅇㅇㄴㅇㅇㅇㄴㅇㅇㅇㄴㅇㅇㅇㄴㅇ"
2. 정규화 과정에서 반복문자를 남겨야 하는 이유
보통 반복문자라고 한다면 문장뒤에 특수기호나 문자가 반복적으로 위치하여 문장에 포함된 정보를 강하게 전달하려는 목적이 있습니다.
한 가지 예시를 들어보겠습니다.
한 개의 문자일 때
뭐하냐 ㅋ
x신 ㅋ
개웃기네 ㅋ
복수개의 문자일 때
뭐하냐 ㅋㅋㅋㅋ
x신 ㅋㅋㅋㅋ
개웃기네 ㅋㅋㅋㅋ
한 문자로 많이 등장하는 반복문자는 대표적으로 "ㅋ"이 있습니다. 해당 문자는 반복되는 횟수에 따라 비웃음일 수도 있고 웃음을 뜻하는 것처럼 보입니다. 다시 말해 반복문자가 등장하는 빈도에 따라 전달하는 메시지의 의도가 달라질 수 있거나 일반적인 상황보다 더 과격한 느낌을 전달할 수 있습니다. 그러기에 아예 없애거나 하나로 축약하는 것보다는 어느 정도 반복문자들을 남기는 것이 문장에서 정보의 손실을 최소화할 수 있습니다.
3. 반복문자 정규화 기준 정의
실제로 sns 대화 데이터, 댓글 데이터를 보다 보면 아래와 같은 형태의 반복문자열을 볼 수 있습니다.
| 예시 문장 | 반복 요소 |
| ㅋㅋㅋㅋㅋㅋㅋ | " ㅋ " |
| 에반데.......????? | " . ", " ? " |
| ㄲㅈㄲㅈㄲㅈㄲㅈ (...) | " ㄲㅈ " |
| [emoji][emoji][emoji][emoji][emoji] (...) | " [emoji] " |
| ㅅㅂㅅㅂㅅㅂ | " ㅅㅂ " |
특수문자 취급되는 이모지는 따로 처리할 수 있으나 <happy> 이러한 형식으로 문장에 남아있는 이모지일 경우 같이 처리를 해줘야 합니다.
이러한 반복문자들을 처리할 때 보통 반복문자의 길이가 짧을수록 문장과 관련 있는 정보를 내포할 가능성이 높으며 반복되는 최소 단위인 문자열의 길이가 길수록 일반 문장보다는 spamming(반복 전송 스팸) 형태와 유사하게 됩니다. 그러기에 길이가 길다면 굳이 반복되는 부분을 남겨둘 필요가 없을 확률이 높습니다.
그러기에 해당 포스팅에서는 아래와 같이 기준을 정의하였습니다.
(모든 케이스에서는 해당 기준 초과 시 해당 기준에 일치하는 형태로 교정합니다.
ex. 반복문자 개수가 N개 초과하여 반복 시 N개까지만 유지)
| 글자 갯수 | 반복문자 갯수 |
| 한 글자 | 3개 이외에 반복문자 제거 |
| 두 글자 | 2개 이외에 반복문자 제거 |
| 세 글자 이상 | 첫번째 반복문자 이외에 제거 |
4. 정규화 과정 1 - 반복문자 탐지
한 글자, 두 글자, 세 글자 이상 순서대로 정규표현식을 작성해 보겠습니다.
| 글자 갯수 | 정규표현식 |
| 한글자 | /(\S{1})\1{3,}/ |
| 두글자 | /(\S{2})\1{2,}/ |
| 세글자 이상 | /(\S{3,})\1{1,}/ |
정규표현식의 표현식을 쉽게 정리하면 아래와 같습니다.
| 표현식 | 설명 |
| \S | 공백문자를 제외한 모든 문자 |
| (...) | 소괄호로 표현식들을 묶어 그룹을 형성한다면 그룹 내 표현식으로 탐지된 대상은 하나의 집합으로 취급 |
| x{ N } | 왼쪽에 있는 x값이 N번 반복되면 탐지 |
| x{ N, } | 왼쪽에 있는 x값이 N번 이상이면 반복되면 초과한 모든 대상을 포함하여 탐지됨 |
| \1 | 첫번째로 형성된 그룹을 칭하는 식 |
위의 표를 기준으로 설명하자면 아래와 같습니다.
| 순서 | 정규표현식 | 설명 |
| 1 | /(\S{1})\1{3, }/ | 길이가 1인 반복문자가 총 4회 이상 (그룹 포함) 반복될 시 탐지 |
| 2 | /(\S{2})\1{2, }/ | 길이가 2인 반복문자가 총 3회 이상 (그룹 포함) 반복될 시 탐지 |
| 3 | /(\S{3, })\1{1, }/ | 길이가 3이상인 반복문자가 총 2회 이상(그룹 포함) 반복될 시 탐지 |
여기서 주의해야 할 점은 해당 정규표현식은 그룹화한 식 또한 반복문자를 탐색하기에 \1{3, }이 3회 이상, 그룹화 표현식이 1회 탐색하여 최종 4회 이상 반복될 시 탐지하게 됩니다.
쉬운 이해를 위해 아래의 표를 참조하시면 될 것 같습니다.
해당 표는 쉬운 이해를 위해 자모단위만 사용하였습니다. 실제로는 다양한 문자를 탐색할 수 있으니 참고 바랍니다.
| 문자 갯수 | 예시문장 | 주황 - 그룹, 파랑 - 반복된 그룹 탐색 결과 |
| 1개 | " 어이없내 ㅋㅋㅋㅋㅋㅋ " |
| 2개 | "ㅇㅋㅇㅋㅇㅋ" |
| 3개 이상 | "ㅁㅊㄴㅁㅊㄴ" |
5. 정규화 과정 2 - 반복문자 교정하기
반복문자를 교정하는 데에는 다양한 방법이 존재합니다. 첫 번째는 정규표현식을 통해 탐지한 반복문자열을 가공해서 교정하는 방법과 두 번째는 정규표현식을 통해 반복문자열을 치환하여 교정하는 방법입니다. 아래에서 순서대로 설명하겠습니다.
5-1. 첫 번째 방법 ( 반복문자 길이가 불변적일 경우 )
4. 정규화 과정 1 - 반복문자 탐지에서 사용했던 정규표현식을 통해 반복문자열을 탐지 후 반복문자 길이를 활용하여 최대 반복 횟수에 해당하는 반복문자열의 index값을 기준으로 자르면 기존의 반복문자열을 교정한 결과를 얻게 됩니다. 그리고 탐지한 대상을 해당 결과로 치환하면 되죠.
아래의 예시를 통해 간략하게 설명하겠습니다.
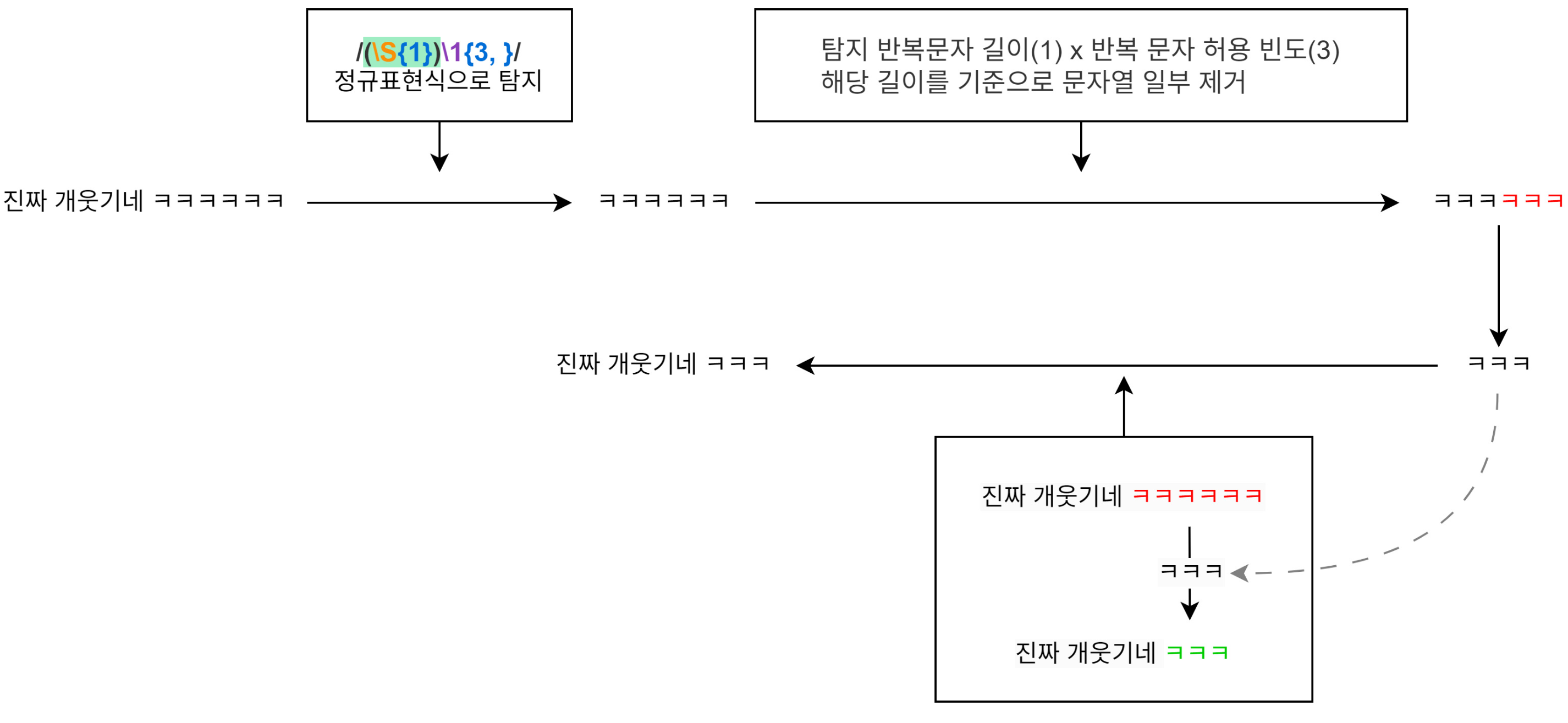
해당 그림에서의 순서는 다음과 같습니다.
- 주어진 문장에서 길이가 1인 반복문자열을 탐지하는 정규 표현식을 활용하여 반복문자열을 탐지합니다.
- 탐지한 반복문자열에서 허용되는 반복 최대 길이만큼의 길이 이외에 문자는 제거합니다.
- 해당 문자열은 반복문자열의 교정 결과입니다. 이제 해당 문자열을 기존 문장의 반복문자열과 치환하면 성공적으로 정규화 과정을 끝내게 됩니다.
해당 과정을 모든 반복문자열을 교정할 때까지 진행합니다.
하지만 해당 방식에는 단점이 있습니다.
해당 방식은 길이가 불변적인 경우에 최적화되어 있습니다. 즉 "길이 3 이상 - 4. 정규화 과정 1 - 반복문자 탐지"와 같은 가변적인 길이에 대응하기 매우 까다롭습니다. 만약 가변적인 문자를 처리하려면 소스코드의 양이 늘어나고 코드 자체가 난잡해지기에 두 번째 방법을 사용하는 것을 권합니다.
5-2. 두번째 방법 ( 문자 길이에 대한 제약사항 없음 )
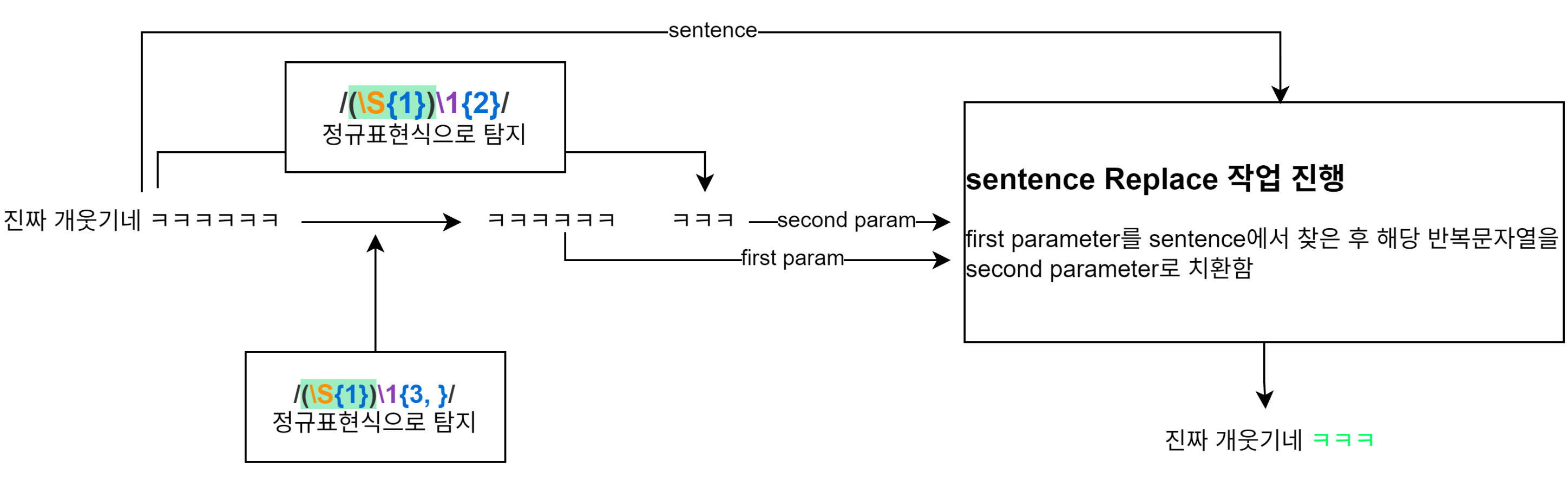
해당 방식은 첫 번째 방법과 같이 문자를 다른 문자열로 치환합니다. 이때 첫 번째로 탐지한 반복문자열을 활용하는 것이 아닌 기존 문장에서 조건에 부합하는 반복문자열을 탐지하여 치환에 사용합니다. 직관적이며 준수한 성능을 기대할 수 있습니다.
하지만 두 번째 방식에서는 조건에 부합하는 반복문자열을 찾는 정규표현식은 앞서 알려드렸던 정규표현식과는 조금 다르기에 아래의 표를 참고하시면 되겠습니다.
| 글자 갯수 | 정규표현식 |
| 한글자 | /(\S{1})\1{2}/ |
| 두글자 | /(\S{2})\1/ |
| 세글자 이상 | /(\S{3,})\1/ |
위의 표를 기준으로 설명하자면 아래와 같습니다.
| 순서 | 정규표현식 | 설명 |
| 1 | /(\S{1})\1{2}/ | 길이가 1인 반복문자가 3회 반복되는 문자열이 탐지 |
| 2 | /(\S{2})\1/ | 길이가 2인 반복문자가 2회 반복되는 문자열 탐지 |
| 3 | /(\S{3, })\1/ | 길이가 3이상인 반복문자가 2회 반복되는 문자열 탐지 |
이때 3번 정규표현식은 식 자체의 한계로 인해 2번 정규표현식과 같이 반복문자가 두번 반복되는 반복문자열을 탐지하게 됩니다. 그러기에 탐지한 반복문자열을 2로 나누어 절반을 삭제하는 과정을 추가적으로 필요합니다.
당연한 이야기겠지만 반복문자가 2번 이상 반복되는 반복문자열을 탐지하기 위한 표현식이기에 반복문자열에서 단일 반복문자를 동시에 탐지하는 데에는 한계점이 있을 수밖에 없습니다. 그러기에 3번 같은 경우엔 예외코드 작성이 필요합니다.
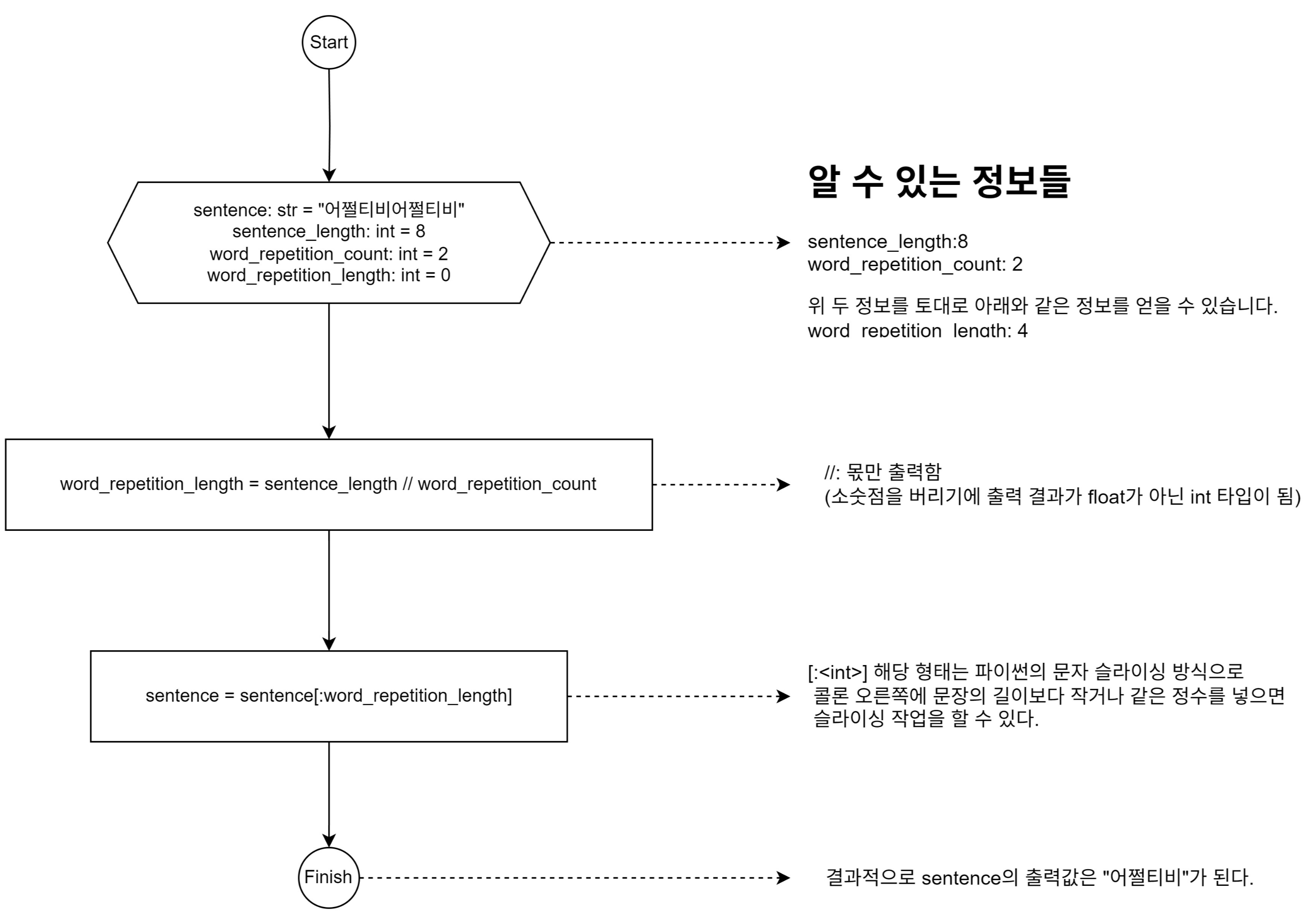
3번 경우에 대한 예외 처리 로직에 대한 설명
3번같은 경우 2번 반복된다는 정보를 알 수 있기에 문자열 길이를 2로 나누어 문자열을 자르기만 하면 됩니다. 쉬운 이해를 위해 아래의 이미지를 참고하시면 될 것 같습니다.
정규표현식의 성능을 좋게 만들고 싶다면..
정규표현식은 일반적으로 O(n)의 시간복잡도로 알려져 있지만 경우에 따라 지수함수 형태의 시간 복잡도 O(n^m) 를 가질 수 있습니다. 그러기에 극한의 성능을 추구한다 싶으면 아래의 스택 오버플로 게시글을 참조하시면 되겠습니다.
What's the Time Complexity of Average Regex algorithms? - Stack Overflow
6. 정리 및 마무리
6-1. 재귀함수로 개발할 때 주의해야 할 점
만약 재귀함수로 구현한다면 깊이가 무한정으로 들어가서 stack overflow가 발생하게 됩니다. 이를 방지하기 위해 해당 language에 있는 stack overflow의 설정값 또는 임의의 임계값을 정하여 해당 기준치를 달성하면 리턴하는 로직을 작성하시는 것을 권합니다.
6-2. 끝내는 말
처음엔 간단한 코딩 결과를 작성하려고 했으나 정규표현식에 대해 설명하자니 너무 길어져 생각보다 알찬 포스팅을 하게 되었네요..ㅎㅎ 그럼에도 자신의 코드를 한번 더 둘러봄과 동시에 정규표현식 최적화 방안 또는 반복문자 정규화 방법 2가지의 퍼포먼스 테스트와 같이 다양한 궁금증이 생겼던 계기가 되었던 것 같습니다. 이 포스트로 전하고자 하는 내용은 단순한 수치가 아닌 탐색 방법에 대한 내용이기에 수치를 바꿔가며 시도하면서 최적의 로직을 구성하길 바라겠습니다. 읽어주셔서 감사합니다!
reference
- https://f7project.tistory.com/383
- https://stackoverflow.com/questions/17680631/python-regular-expression-not-matching
'인공지능' 카테고리의 다른 글
| 데이터 전처리 과정 <1> | 정규화 방식을 구상할 때 고려해야 할 점 (0) | 2025.02.24 |
|---|---|
| 인공지능을 이용한 딥러닝 욕설 필터링 모델 만들기 - 2번째 (학습 단계) (0) | 2023.07.22 |
| 인공지능을 이용한 딥러닝 욕설 필터링 모델 만들기 - 1번째 (전처리 단계) (0) | 2023.07.20 |
| 한국어 비속어 데이터셋 모음 + (비속어 정규식) (0) | 2023.07.20 |
| 강력한 음성변조 모델 RVC ai 사용하기 (환경설정 및 실행) (0) | 2023.07.09 |